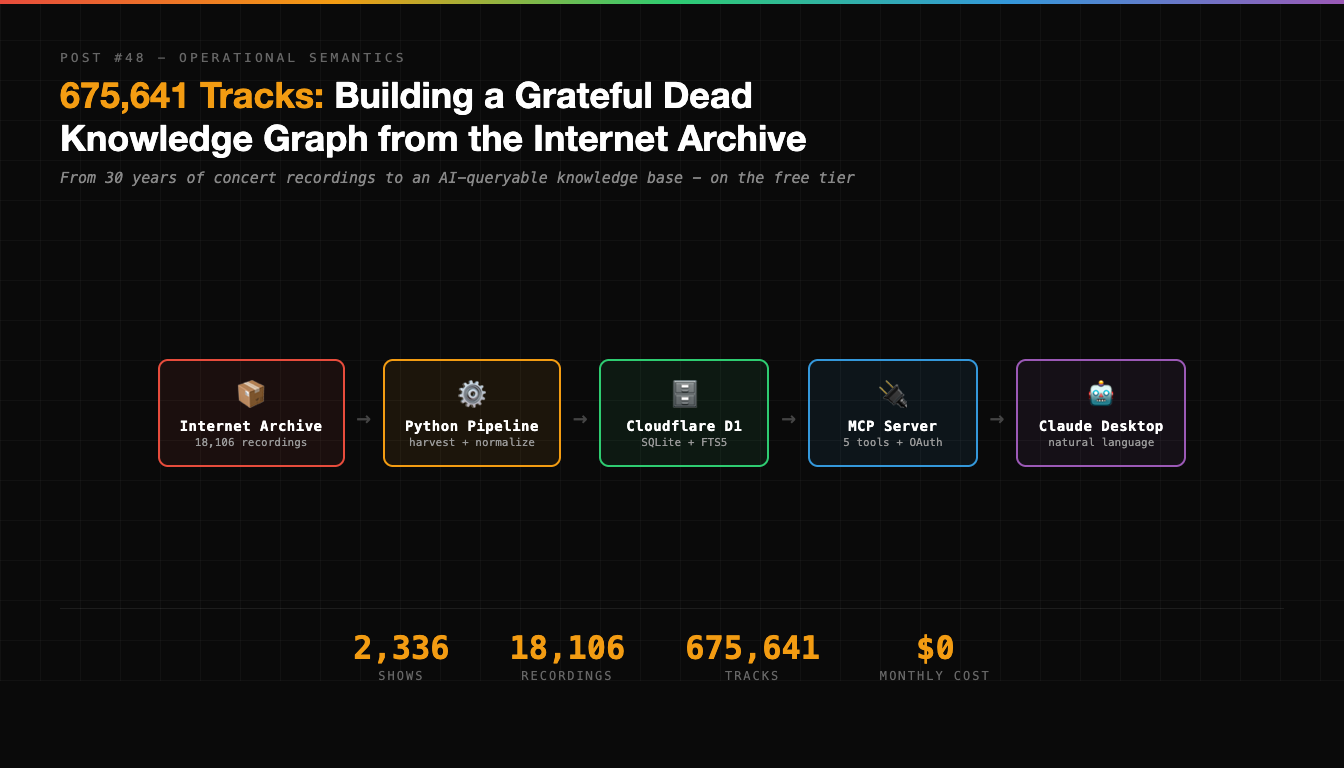
675,641 Tracks: Building a Grateful Dead Knowledge Graph from the Internet Archive
How I turned 30 years of Grateful Dead concert recordings into a tool Claude can query - and the moment ChatGPT almost killed the whole project
There are 18,106 recordings of the Grateful Dead on the Internet Archive. Community-uploaded, freely available, spanning 30 years and 2,336 shows. Audience recordings, soundboards, matrix mixes - every format you can imagine, from every venue they ever played.
I turned all of it into a tool Claude can query with natural language.
This is the story of how I harvested the Internet Archive, normalized 30 years of messy concert metadata into a knowledge graph, deployed it on Cloudflare’s free tier, and then had a full existential crisis when ChatGPT answered the same questions without any of my infrastructure.
Spoiler: the crisis was unjustified. But I didn’t know that yet.
Why the Grateful Dead?
I know some deeply knowledgeable Deadheads. A guy who teaches rock history at Stanford. Assorted folks in close orbit with the band. Avid, lifelong audiophile followers who know their Dead history cold - the kind of people who can tell you the setlist for any show in 1977 from memory.
The Internet Archive has the data - the Dead were famously tape-friendly, and their fans uploaded everything - but the IA’s search interface isn’t exactly optimized for questions like “show me every Dark Star longer than 30 minutes” or “what was the setlist at Cornell in 1977?”
The idea was simple: harvest the metadata, structure it, and serve it through an AI-native interface. Build a tool these people could actually use - one that answers Dead trivia with citations and direct links to recordings, not hallucinated factoids.
The implementation was… less simple.
Phase 1: The Harvest
The Internet Archive exposes a search API. For the Grateful Dead collection, that means roughly 18,000 items, each containing metadata about a specific recording - date, venue, taper, source type, track listings, community ratings.
I wrote an async harvester in Python using httpx and tenacity for retry logic:
# 5 retries with exponential backoff, shared HTTP client
# Paginated at 2,000 results per page
async def harvest_collection():
async with httpx.AsyncClient(timeout=60) as client:
page = 1
while True:
results = await fetch_page(client, page)
if not results:
break
yield from results
page += 1The harvest pulled down two files: ia_docs.json (the search results) and ia_meta.json (detailed metadata for each item). About 18,106 recordings total. This part was straightforward - the IA’s API is well-documented and reliable.
The interesting problems started when I tried to make sense of it all.
Phase 2: The Venue Problem
Here’s something you don’t think about until you’re knee-deep in 30 years of concert metadata: venues have names, and people are terrible at spelling them consistently.
The raw data from the Internet Archive had 3,144 unique venue strings. For a band that played roughly 2,336 distinct shows. That’s a lot of duplicates.
Some examples of what I was dealing with:
"Winterland Arena"
"Winterland"
"Winterland, San Francisco"
"Winterland, SF, CA"
"Winterland Arena, San Francisco, CA"All the same place. And that’s one of the easier ones.
I built a canonicalization pipeline that:
- Slugified venue names into URL-safe strings (
winterland-arena) - Clustered venues by date + location similarity
- Merged recordings from the same show into a single canonical entity
The result: 3,144 venue strings collapsed into 2,336 unique shows. Each show got a stable ID following a consistent format:
gd:show:1977-05-08:barton-hall---cornell-university
gd:rec:gd1977-05-08.sbd.hicks.4982.sbeok.flac16Every recording links to its show. Every track links to its recording. The entity model is simple:
Show (2,336)
|-- Recording (18,106)
|-- Track (675,641)That’s 675,641 individual tracks. Every song the Grateful Dead played at every show, from every recording angle, with durations and titles.
Phase 3: The Pipeline
I’m a believer in make-based pipelines for data work. Each step is a standalone script, each step is independently testable, and the Makefile documents the dependency order:
make harvest # Internet Archive -> data/raw/
make canonical # Raw -> shows.jsonl, recordings.jsonl, tracks.jsonl
make enrich # Song statistics, segue detection
make filter # Apply rights/license policy
make rag # Build search indexThe filter step matters. The Internet Archive is permissive, but not everything there is licensed for redistribution. I wrote a policy.yaml that controls what gets through:
- Allowed licenses: CC0, CC-BY, CC-BY-NC, Public Domain
- Blocked sources: setlist.fm (retention restrictions)
- Soundboard recordings: metadata and links only, no audio mirroring
- Lyrics: excluded unless written permission obtained
Every filtering decision gets logged to an audit trail. This is a rights-aware system, not a scraper.
The test suite hit 155 tests at 100% coverage. Not because I’m obsessive (okay, partly), but because data pipelines are exactly the kind of thing that breaks silently. A wrong field mapping or a bad string parse doesn’t throw an error - it just produces subtly wrong data that you discover weeks later. Tests catch that.
Phase 4: Going Cloud
The pipeline worked locally. JSONL files, a FastAPI server, search endpoints. But the whole point was making this accessible through Claude Desktop - which means it needed to be a remote MCP server.
MCP - Model Context Protocol - is the standard for connecting AI assistants to external tools. Claude Desktop supports it natively. You point it at a URL, authenticate, and suddenly Claude can call your tools as part of its reasoning.
I chose Cloudflare Workers + D1 for the hosting. Here’s why:
Free tier: 5 GB database storage, 5 million reads/day, 100,000 requests/day, zero egress cost. My dataset is 273 MB. That’s 5.4% of the free allocation.
D1 is SQLite: Which means FTS5 full-text search comes built in. No separate search service needed. No Elasticsearch. No Algolia. Just CREATE VIRTUAL TABLE shows_fts USING fts5(id, date, venue_name) and you’ve got instant full-text search on your data.
Workers run everywhere: Cloudflare’s edge network means sub-100ms latency for most users without any CDN configuration.
The schema is minimal:
CREATE TABLE shows (
id TEXT PRIMARY KEY,
date TEXT NOT NULL,
venue_name TEXT NOT NULL,
source_count INTEGER DEFAULT 0,
people TEXT -- JSON array string
);
CREATE TABLE recordings (
id TEXT PRIMARY KEY,
show_id TEXT NOT NULL,
ia_identifier TEXT NOT NULL,
source_type TEXT,
lineage TEXT,
taper TEXT,
avg_rating REAL,
publicdate TEXT
);
CREATE TABLE tracks (
rec_id TEXT NOT NULL,
track_num INTEGER NOT NULL,
title TEXT,
duration_sec INTEGER,
PRIMARY KEY (rec_id, track_num)
);
CREATE VIRTUAL TABLE shows_fts USING fts5(id, date, venue_name);
CREATE VIRTUAL TABLE tracks_fts USING fts5(title, rec_id);Three tables, two FTS5 virtual tables, three indexes. That’s the entire database.
Phase 5: The Things That Broke
This is where the story gets honest.
SQLITE_TOOBIG
My first attempt at seeding the D1 database used batch inserts of 500 rows per statement. Turns out D1 has an approximately 100KB maximum statement size. 500 rows of track data - with long titles and metadata - blew right past that.
The fix was unglamorous: smaller batches. 50 rows for tracks, 200 for shows and recordings. The seed script now generates ~13,600 individual SQL statements, and the full seed takes about 12 seconds to execute against remote D1.
BEGIN TRANSACTION: Not Allowed
My seed script wrapped everything in BEGIN TRANSACTION / COMMIT for atomicity. Perfectly reasonable for SQLite. Remote D1 rejected it completely - it manages transactions internally and doesn’t allow explicit transaction control.
I found this out at deployment time, not during local testing, because local D1 (via wrangler dev) is more permissive than remote D1. A good reminder that local dev environments lie to you.
The OAuth Comedy
The MCP server uses OAuth 2.1 with PIN-based authentication. Claude Desktop connects, gets redirected to a login page, you enter a PIN, and you’re in.
During testing, I connected via MCP Inspector and got invalid_token. I spent an hour adding development bypass routes, fake OAuth endpoints, and environment-aware auth skipping. Then I realized: I’d entered the PIN wrong.
Let me be blunt: I built an entire authentication bypass system because I typo’d a password.
After reverting all of that code (every line of it), the OAuth flow worked perfectly on the first try. The lesson isn’t about OAuth. It’s about checking the simple explanation before building the complex workaround.
Phase 6: The Five Tools
The MCP server exposes five tools that Claude Desktop can call:
search_shows - Full-text search across shows. “cornell 1977” finds Barton Hall. “winterland” finds all 89 Winterland shows. FTS5 handles the search with LIKE as a fallback for special characters.
get_show - Given a show ID, returns the date, venue, musicians, and every available recording sorted by community rating. Each recording includes a direct Archive.org link.
get_setlist - The track listing for a specific recording with song durations. “What did they play at Cornell?” becomes answerable with actual track times.
search_songs - Find every performance of a song across the entire archive. “Dark Star” returns 233 unique show dates with venues and durations.
get_stats - The summary: 2,336 shows, 18,106 recordings, 675,641 tracks, 1965-1995.
Each tool does FTS5 search first and falls back to LIKE queries if FTS5 chokes on special characters. The search_songs tool deduplicates by show date - important because the same show might have 8 different recordings, and you don’t want “Dark Star” listed 8 times for the same night.
That dedup logic had its own bug. I was originally keying on show_date + title, which treated “Dark Star”, “Dark Star >”, and “Dark Star ->” as different entries. They’re not - they’re the same performance, just labeled differently by different tapers to indicate segues. Changing the key to just show_date fixed it, jumping from 57 results to 233.
The ChatGPT Crisis
Here’s where the story takes a turn.
After deploying the MCP server, I asked ChatGPT: “How many times did the Grateful Dead perform Dark Star?” It said 234, noting the official count is argued to be 235. My database found 233 unique show dates with Dark Star in the track listing. Close enough on all sides - the discrepancies come down to what counts as a “performance” vs. a tease or an aborted start.
I stared at my terminal. I’d just spent weeks building a data pipeline, writing 155 tests, designing a schema, debugging OAuth, deploying to Cloudflare - and ChatGPT could answer the same question from training data. The counts roughly agreed. What exactly was the point of all this?
I had a genuine “what am I doing here” moment.
Then I asked a harder question: “What was the longest Dark Star performance?”
ChatGPT said the 2/18/1971 performance at the Capitol Theatre, “often cited as around 40 minutes.” Confident. Authoritative. Wrong.
I ran the actual query against my database. The longest Dark Star in the archive is from 1969-02-28 at the Family Dog at the Great Highway - 47 minutes and 32 seconds. Not close to what ChatGPT said.
Here’s what my tool returned that ChatGPT couldn’t:
1969-02-28 - Family Dog at the Great Highway [47:32]
Listen: https://archive.org/details/gd1969-02-28.sbd.miller.32196.sbeok.flac16
1970-02-14 - Fillmore East [44:24]
Listen: https://archive.org/details/gd1970-02-14.sbd.miller.89286.flac16
1971-02-18 - Capitol Theatre [40:58]
Listen: https://archive.org/details/gd1971-02-18.sbd.miller.89904.flac16Every result is verifiable. Every result links to the actual recording you can listen to right now. ChatGPT gave a plausible-sounding answer that happened to be wrong. My database gave exact durations from actual recordings.
This is the fundamental difference between an LLM answering from training data and a structured knowledge base. The LLM can tell you facts that feel right. The database can tell you facts that are right - with exact durations, links to the source material, and no hedging about “often cited as around.”
The Architecture, All Together
The final system has five tiers, from source to client:
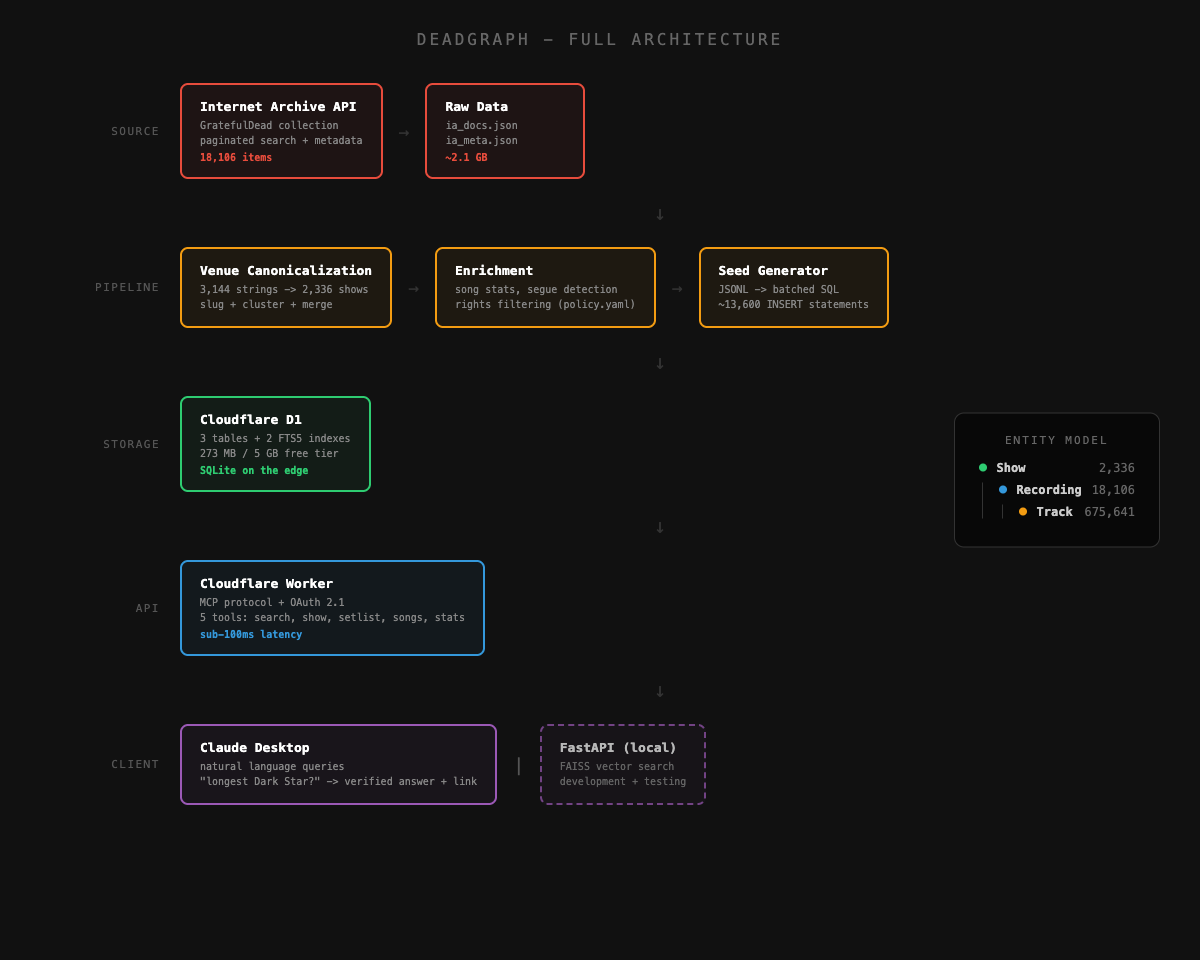
The data pipeline is Python. The MCP server is TypeScript. The database is SQLite (via D1). The auth is OAuth 2.1 with a PIN. The whole thing runs on Cloudflare’s free tier.
Total ongoing cost: $0.
What I’d Do Differently
Start with D1 schema design, not JSONL. I designed the JSONL format first and then adapted it for D1. Working backwards meant I had fields in the JSONL that D1 didn’t need and vice versa. Schema-first would have saved a round of refactoring.
Test against remote D1 earlier. Local D1 via wrangler dev is more permissive than remote D1. The transaction issue and the statement size limit both only surfaced during remote deployment. Testing against remote D1 from the start would have caught these day one.
Don’t build workarounds before checking your inputs. The OAuth bypass I built was entirely unnecessary. The login worked fine - I just entered the wrong PIN. Always check the simple explanation first.
What’s Next
The MCP server is live. The Deadheads in my circle are the first testers. The vision is a research tool that can answer questions like:
- “Show me every time Dark Star segued into St. Stephen”
- “What songs did they only play once?”
- “Compare the setlists from Europe ‘72 to the Spring 1977 tour”
The data supports all of these queries. The tools need to get smarter - more complex joins, date range filters, segue tracking from the enrichment pipeline. But the foundation is solid: 2,336 shows, 18,106 recordings, 675,641 tracks, all indexed and searchable through natural language.
Every answer links back to a recording on the Internet Archive. Every recording is freely accessible. No copyright violations. No hallucinated facts.
Just 30 years of the Grateful Dead, structured and searchable.
What a long strange trip it’s been.